Het robots.txt bestand is een tekstbestand met instructies voor zoekmachinerobots, bijvoorbeeld van Google. Dit instructiebestand vertelt zoekmachinerobots (ook wel crawlers) welke URL’s van een bepaalde website zij niet of juist wel moeten bezoeken. Door bepaalde pagina’s uit te sluiten, voorkom je dat pagina’s van lage kwaliteit of met weinig relevantie (zoals de /wp-admin/ pagina) worden gecrawld. Hiermee voorkom je dat ongewenste pagina’s in de zoekresultaten belanden. Dit scheelt de crawlbot vervolgens ook weer tijd bij het indexeren van jouw pagina’s.
Waar je je goed van bewust moet zijn is dat een robots.txt bestand slechts richtlijnen betreft. De crawlbots van grote zoekmachines als Google respecteren de inhoud van het bestand, maar het blijven richtlijnen, geen regels. Wil je dat een pagina niet terugkomt in bijvoorbeeld de zoekresultaten van Google? Dan kun je de pagina beter op no-index zetten.
Waarom is het robots.txt bestand belangrijk?
Het robots.txt bestand is belangrijk, omdat het je in staat stelt om zoekmachines toegang te ontzeggen tot bepaalde gedeeltes van je site. Bovendien kun je er duplicate content mee voorkomen en bij zoekmachines aangeven hoe zij efficiënt jouw site kunnen crawlen. Met het robots.txt bestand zorg je er namelijk voor dat de server van je website niet wordt overladen met verzoeken van bots. Zo voorkom je dat crawlers tijd verspillen door onnodige delen van jouw website te scannen.
Wist je bovendien dat crawlers een zogenaamd crawlbudget hebben? Dat is een limiet dat bepaalt hoe vaak crawlers langskomen op jouw website en hoeveel pagina’s ze van je site scannen. Heb je een enorme webshop met veel irrelevante pagina’s en geen robots.txt bestand ingesteld? Dan is dat hartstikke zonde van het crawlbudget. Een zoekmachine zal dit budget namelijk voor een gedeelte gebruiken om pagina’s te scannen die onbelangrijk zijn, zoals bedankpagina’s, interne zoekopdrachten of een admin-pagina.
Vanuit SEO-oogpunt kan een robots.txt bestand ook van invloed zijn. Zo kun je middels dit bestand de crawlers leiden naar jouw sitemap, dat alle links van je website bevat. Wijs je de crawler de juiste weg en heb je irrelevante pagina’s in het robots.txt bestand uitgesloten? Dan kunnen nieuwe pagina’s sneller worden geïndexeerd en is jouw content net wat beter te vinden.
Definities van elementen uit robots.txt
Wanneer de zoekmachinerobot het robots.txt bestand heeft opgehaald, zijn er 3 uitkomstmogelijkheden:
- full allow (volledig toegestaan): alle inhoud mag worden gecrawld
- full disallow (volledig niet toegestaan): de inhoud mag niet worden gecrawld.
- conditional allow (voorwaardelijk toegestaan): de instructies in het robots.txt-bestand bepalen welke inhoud mag worden gecrawld.
De volgende elementen kunnen in het robots.txt voorkomen. Elke richtlijn dient op een nieuwe regel opgenomen te worden.
- user-agent
- disallow
- allow
- sitemap
User-agent
Dit element wordt gebruikt om aan te geven voor welke crawler de groep geldig is. Alleen voor Google-bots of alle bots bijvoorbeeld. In het voorbeeld hieronder is er een user-agent speciaal voor de Ravencrawler en een user-agent met daaronder regels voor alle bots.
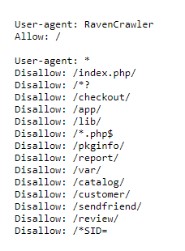
De volgende user-agents kun je onder andere tegenkomen:
- * – De regels gelden voor elke bot, tenzij er sprake is van een meer specifieke set regels
- Googlebot – Alle Google crawlers
- Googlebot-Image – Crawler voor Google Afbeeldingen
- Bingbot – Crawler van Bing
Disallow
Met de instructie disallow wordt aangegeven welke paden niet gevolgd mogen worden door de toegewezen crawlers. Wanneer er geen pad is opgegeven, wordt de instructie genegeerd.
Allow
Met allow wordt aangegeven welke paden de toegewezen crawlers wel mogen bezoeken. Ook hier geldt: wanneer er geen pad is opgegeven, wordt de instructie genegeerd.
Sitemap
Met het element ‘sitemap’ kan de locatie van de sitemap aangegeven worden.
Hoe ziet een robots.txt bestand eruit?
Een robots.txt-bestand kan er als volgt uitzien:
Een pagina uitsluiten
Met user-agent geef je aan voor welke zoekmachines de richtlijnen zijn bedoeld. Het sterretje (*) betekent dat het bestand geldt voor alle zoekmachines. Achter ‘disallow’ plaats je vervolgens het pad dat niet toegankelijk is voor de zoekmachine. Het pad /wp-admin/ verwijst in dit geval naar de admin-pagina van een website.
User-agent: *
Disallow: /wp-admin/
Kortom: dit robots.txt bestand vertelt alle zoekmachines dat /wp-admin/ niet toegankelijk is voor ze.
Disallow: /
Zorg ervoor dat je nooit de regel ‘Disallow: /’ opneemt in het robots.txt bestand. In dit geval sluit je alle URL’s binnen de website uit. Dit kan wel toegepast worden wanneer jouw website in aanbouw is, en je niet wilt dat Google jouw pagina’s crawlt (en dus indexeert). Maar in dat geval is een no-index tag een slimmere keuze. De regels in robots.txt zijn slechts een richtlijn voor de crawlers. De pagina’s kunnen zonder no-index tag alsnog geïndexeerd worden. Kies je voor dit laatste, laat dan de disallow weg uit het robots.txt bestand. Anders kunnen de crawlers de no-index tag niet zien.
User-agent: *
Disallow: /
Allow en disallow
Je kan er echter ook voor kiezen om een allow-attribuut toe te voegen. Dit stukje code doet het tegenovergestelde van de disallow richtlijn en wordt alleen ondersteund door Google en Bing. Door allow en disallow als combinatie te gebruiken, kun je er alsnog voor zorgen dat bepaalde bestanden of pagina’s binnen een directory toegankelijk zijn.
User-agent: *
Allow: /media/seo-checklist.pdf
Disallow: /media/
Hiermee vertel je een zoekmachine dat het toegang heeft tot de SEO-checklist, maar dat het wordt buitengesloten van de media directory.
Sitemap in robots.txt
Door je sitemap toe te voegen aan het robots.txt-bestand, stel je de robot in staat gelijk de wegenkaart van je website te vinden. Daardoor kan de robot gemakkelijk jouw website crawlen. De sitemap plaats je als absolute URL. Dit ziet er in het robots.txt bestand als volgt uit:
User-agent: *
Disallow: /wp-admin/
Sitemap: https://www.jouwwebsite.nl/sitemap.xml
Richtlijnen robots.txt-bestand
Wil je een robots.txt bestand aanmaken? Neem dan de volgende stappen in acht:
- Zet het bestand in de root directory van je website.
- Schrijf kleine letters in de bestandsnaam (robots.txt en géén Robots.Txt)
- Gebruik voor elke richtlijn een nieuwe regel
- Sla het bestand op als tekstbestand (.txt)
- Test het bestand via de Google robots.txt-tester
Aandachtspunten robots.txt
Tot slot hebben we nog een aantal aandachtspunten wat betreft het robots.txt bestand voor je opgesomd.
- Een robots.txt-bestand mag niet groter zijn dan 500 kb. Is je bestand groter? Dan wordt de inhoud na het maximum genegeerd.
- Het robots.txt-bestand bevat slechts richtlijnen.
- Pagina’s die worden uitgesloten in het robots.txt-bestand, kunnen nog steeds verschijnen in de zoekresultaten wanneer ze gelinkt worden vanaf een pagina die wel gecrawld wordt.







